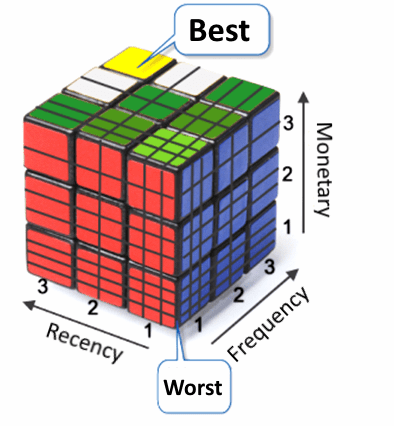
當公司對外行銷或提供服務時,總會希望對VIP客戶特別照顧(大小眼?),因為他們對公司的貢獻度特別大,那我們如何衡量貢獻度或『客戶終身價值』(Customer Lifetime Value, CLV)呢? 最簡單的方法就是統計每個客戶的購買金額,金額越高的就是VIP。真的是這樣嗎? 以筆者本身為例,我要結婚時,到朋友介紹的家具行購買全套的家具,購買金額不低,但後來就沒有再光顧該店了,因為離家太遠了。所以,我們應該加一點『特徵工程』(Feature Engineering),將單純的銷售記錄轉換成更有意義的指標。

圖片來源:善用「終身價值類似受眾」,創造最大收益率
在CRM(客戶關係管理)系統中,通常會將銷售記錄轉化為RFM(Recency, Frequency, Monetary) 三個面向來衡量客戶的貢獻度,說明如下:
綜合以上三個指標,計算分數,找出總分比較高的族群強力行銷,以攻佔他們的荷包(Wallet Share)。
如果以傳統的作法,我們可以將顧客終身價值以三個指標構成一個公式如下:
顧客終身價值(CLV or LTV)=平均貢獻區間 x(一年總週數 x 每次平均消費金額 x 一週平均造訪次數 x 每位顧客的平均毛利率)
詳細說明請參考『顧客終身價值是什麼?把握三種常見的LTV公式幫助預算評估』
這種作法簡單直覺,每一個指標的重要性都相等,不需要複雜的計算,但是,缺點也很明顯,如果把消費金額的單位由元改為萬元,或造訪次數由週改為年,計算的結果就大相逕庭了,因此,一般會使用集群(Clustering)演算法,以求得更完善的模型。
註: 『Understanding Customer Lifetime Value In Retail』 有更細緻的計算公式介紹,有興趣的讀者可自行參閱。
開始之前,先介紹機器學習的處理流程,共10個步驟如下: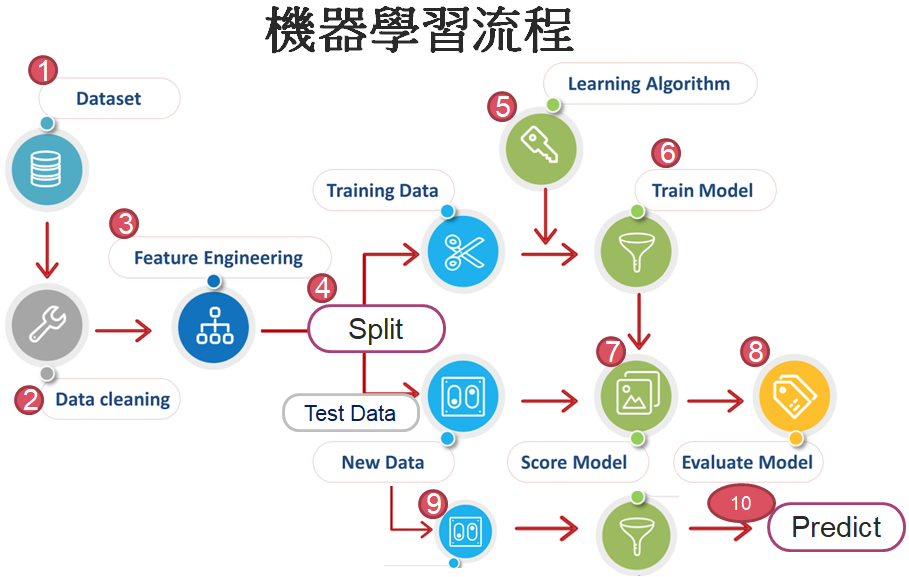
圖片來源:Free Machine learning diagram,筆者作了局部的修改。
之後的案例都會依據上述步驟,按部就班的進行。
筆者參考『RFM-Analysis』一文,它使用的是 UCI 提供的一份線上零售記錄(Online Retail Data Set),為了便於說明,我將流程及資料簡化,以利讀者聚焦在RFM處理與客戶分群。
首先,我們先要上述資料集簡化,只選取英國的銷售資料,且僅包括以下欄位:
讀取檔案的程式如下,將日期轉成年月,以便作月統計:
import pandas as pd
import numpy as np
df = pd.read_csv("./data.csv",converters={'CustomerID':str})
# 轉成年月
df['date']=df.InvoiceDate.astype(np.str).str.slice(0,8).str.replace('-','')
df['date'] = pd.to_numeric(df['date'], errors='coerce')
我事先已完成資料清理步驟,直接進行特徵工程,依據購買日期、發票金額,分別統計 -- 最近購買日期(Recency)、購買頻率(Frequency)及購買金額(Monetary)。
# 計算最近購買日期(Recency)
def f(row):
if row['date'] > 201110:
val = 5
elif row['date'] <= 201110 and row['date'] > 201108:
val = 4
elif row['date'] <= 201108 and row['date'] > 201106:
val = 3
elif row['date'] <= 201106 and row['date'] > 201104:
val = 2
else:
val = 1
return val
df_recency=df[['CustomerID','date']].drop_duplicates()
df_recency['Recency_Flag'] = df_recency.apply(f, axis=1)
df_recency = df_recency.groupby('CustomerID',as_index=False)['Recency_Flag'].max()
Cust_freq=df[['InvoiceNo','CustomerID']].drop_duplicates()
#Calculating the count of unique purchase for each customer
Cust_freq_count=Cust_freq.groupby(['CustomerID'])['InvoiceNo'].aggregate('count').\
reset_index().sort_values('InvoiceNo', ascending=False, axis=0)
# Dividing in 5 equal parts
unique_invoice=Cust_freq_count[['InvoiceNo']]
unique_invoice['Freqency_Band'] = pd.qcut(unique_invoice['InvoiceNo'], 5)
unique_invoice=unique_invoice[['Freqency_Band']].drop_duplicates()
將頻率分成五個區間:
def f2(row):
if row['InvoiceNo'] < 1:
val = 1
elif row['InvoiceNo'] <= 2:
val = 2
elif row['InvoiceNo'] <= 3:
val = 3
elif row['InvoiceNo'] <= 6:
val = 4
else:
val = 5
return val
Cust_freq_count['Freq_Flag'] = Cust_freq_count.apply(f2, axis=1)
#Calculating the Sum of total monetary purchase for each customer
Cust_monetary = df.groupby(['CustomerID'])['Total_Price'].aggregate('sum').\
reset_index().sort_values('Total_Price', ascending=False)
# splitting Total price in 5 parts
unique_price=Cust_monetary[['Total_Price']].drop_duplicates()
unique_price=unique_price[unique_price['Total_Price'] > 0]
unique_price['monetary_Band'] = pd.qcut(unique_price['Total_Price'], 5)
unique_price=unique_price[['monetary_Band']].drop_duplicates()
將購買金額分成五個區間
def f3(row):
if row['Total_Price'] <= 243:
val = 1
elif row['Total_Price'] > 243 and row['Total_Price'] <= 463:
val = 2
elif row['Total_Price'] > 463 and row['Total_Price'] <= 892:
val = 3
elif row['Total_Price'] > 892 and row['Total_Price'] <= 1932:
val = 4
else:
val = 5
return val
Cust_monetary['Monetary_Flag'] = Cust_monetary.apply(f3, axis=1)
Cust_All=pd.merge(df_recency,Cust_freq[['CustomerID','Freq_Flag']], on=['CustomerID'],how='left')
Cust_All=pd.merge(Cust_All,Cust_monetary[['CustomerID','Monetary_Flag']], on=['CustomerID'],how='left')
Cust_All.head(10)
為免篇幅過長,造成讀者消化不良,明天再續。
相關程式碼放在這裡 的 Day02 Customer Segmentation 目錄。